Konfigurasi ketersedian Azure VM
Membuat availability sets
Availability set adalah fitur logic yang digunakan untuk memastikan sekelompok mesin virtual yang saling terkait ditempatkan bersama untuk mencegah satu titik kegagalan memengaruhi semua mesin.
Hal yang Perlu Diketahui tentang Availability Set
- Semua mesin virtual dalam satu availability set sebaiknya menjalankan fungsi yang sama dan memiliki perangkat lunak yang sama.
- Azure memastikan mesin virtual dalam availability set dijalankan pada berbagai server fisik, rak komputasi, unit penyimpanan, dan switch jaringan yang berbeda.
- Pengguna dapat membuat mesin virtual dan availability set secara bersamaan.
- Mesin virtual hanya dapat ditambahkan ke availability set saat dibuat. Untuk memindahkan VM ke availability set lain, pengguna harus menghapus dan membuat ulang VM tersebut.
- Microsoft menyediakan Service Level Agreement (SLA) yang kuat untuk VM Azure dan availability set.
Hal yang Perlu Dipertimbangkan saat Menggunakan Availability Set
Berikut beberapa prinsip perencanaan yang perlu diperhatikan:
- Redundansi: Tempatkan beberapa mesin virtual dalam availability set untuk mencapai konfigurasi yang redundan.
- Pemisahan Tier Aplikasi: Setiap tier aplikasi (misalnya web, aplikasi, database) sebaiknya berada pada availability set yang terpisah untuk menghindari titik kegagalan tunggal.
- Load Balancing: Untuk ketersediaan tinggi dan performa jaringan, buat availability set yang dibebani secara seimbang menggunakan Azure Load Balancer. Load Balancer akan membagi lalu lintas masuk ke instance layanan yang aktif.
- Disk Terkelola: Gunakan disk terkelola Azure (Azure managed disks) bersama dengan mesin virtual dalam availability set untuk penyimpanan level blok yang andal.
Review tentang update domains and fault domains
Availability Set pada Azure Virtual Machine menggunakan dua konsep penting untuk menjaga ketersediaan tinggi (high availability) dan toleransi terhadap kegagalan (fault tolerance) saat menerapkan dan memperbarui aplikasi, yaitu update domain dan fault domain.
Setiap mesin virtual dalam availability set akan ditempatkan pada satu update domain dan satu fault domain.
Hal yang Perlu Diketahui tentang Update Domain
Update domain adalah sekelompok node yang diperbarui bersama selama proses peningkatan layanan (upgrade atau rollout). Update domain memungkinkan Azure untuk melakukan pembaruan secara bertahap.
Ciri-ciri update domain:
- Setiap update domain berisi satu set mesin virtual dan perangkat keras fisik yang dapat diperbarui dan direboot secara bersamaan.
- Selama pemeliharaan terencana, hanya satu update domain yang direboot dalam satu waktu.
- Secara default terdapat lima update domain (tidak dapat dikonfigurasi oleh pengguna).
- Pengguna dapat mengatur hingga 20 update domain jika diperlukan.
Hal yang Perlu Diketahui tentang Fault Domain
Fault domain adalah sekelompok node yang mewakili satu unit fisik dari kemungkinan kegagalan. Fault domain biasanya mencerminkan node-node dalam satu rak server fisik.
Ciri-ciri fault domain:
- Fault domain mendefinisikan grup mesin virtual yang berbagi satu set perangkat keras atau switch jaringan yang memiliki titik kegagalan yang sama.
- Contoh: satu rak server dengan satu set sumber daya daya listrik atau switch jaringan.
- Dua atau lebih fault domain digunakan bersama untuk mengurangi risiko kegagalan perangkat keras, gangguan jaringan, pemadaman listrik, atau pembaruan perangkat lunak.
Contoh Skenario
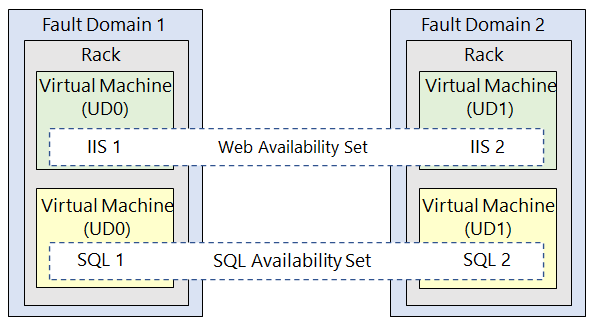
Bayangkan pengguna memiliki dua fault domain, masing-masing berisi dua mesin virtual. Mesin-mesin virtual ini tersebar dalam dua availability set berbeda:
- Availability Set Web: berisi dua mesin virtual, masing-masing berada di fault domain yang berbeda.
- Availability Set SQL: juga berisi dua mesin virtual, masing-masing dari fault domain yang berbeda.
Dengan pengaturan ini, jika terjadi kegagalan pada salah satu fault domain, sebagian besar layanan tetap tersedia karena mesin virtual lainnya berada di fault domain yang berbeda.
Review availability zone
Availability zone adalah fitur ketersediaan tinggi yang melindungi aplikasi dan data pengguna dari kegagalan data center. Di dalam satu region Azure, availability zone merupakan kombinasi dari fault domain dan update domain.
Jika pengguna membuat tiga atau lebih mesin virtual di tiga zone dalam satu region Azure, mesin-mesin virtual tersebut akan tersebar secara efektif ke tiga fault domain dan tiga update domain. Azure mengenali distribusi ini dan memastikan bahwa pembaruan tidak dilakukan secara bersamaan pada mesin virtual di zona yang berbeda.
Pengguna dapat membangun arsitektur aplikasi dengan ketersediaan tinggi menggunakan availability zones dengan menempatkan (colocate) sumber daya komputasi, penyimpanan, jaringan, dan data Pengguna dalam satu zona dan melakukan replikasi ke zona lainnya.
Hal yang Perlu Diketahui tentang Availability Zone
- Availability zone adalah lokasi fisik yang unik dalam satu region Azure.
- Setiap zona terdiri dari satu atau lebih data center dengan daya, pendingin, dan jaringan yang mandiri.
- Untuk menjamin ketahanan, setiap region yang mendukung availability zone memiliki minimal tiga zona yang terpisah secara fisik.
- Pemisahan fisik antar zona dalam satu region melindungi aplikasi dan data dari kegagalan data center.
- Layanan yang redundant terhadap zona (zone-redundant services) mereplikasi aplikasi dan data Pengguna ke beberapa zona untuk menghindari titik kegagalan tunggal (single point of failure).
Hal yang Perlu Dipertimbangkan saat Menggunakan Availability Zone
Layanan Azure yang mendukung availability zone terbagi dalam dua kategori:
| Kategori | Deskripsi | Contoh Layanan |
|---|---|---|
| Zonal services | Setiap resource ditempatkan pada satu zona tertentu. | - Azure Virtual Machines - Azure Managed Disks - Standard IP Addresses |
| Zone-redundant services | Platform Azure akan secara otomatis mereplikasi layanan ke seluruh zona. | - Azure Storage dengan zone-redundancy - Azure SQL Database |
Untuk mencapai business continuity yang menyeluruh di Azure, bangun arsitektur aplikasi Pengguna dengan kombinasi availability zones dan Azure regional pairs.
Perbandingan vertical dan horizontal scaling
Konfigurasi mesin virtual yang tangguh mencakup dukungan terhadap skalabilitas. Skalabilitas memungkinkan mesin virtual menangani beban kerja lebih besar seiring dengan ketersediaan sumber daya perangkat keras yang digunakan. Dua pendekatan utama untuk skalabilitas adalah skala vertikal dan skala horizontal.
Skala Vertikal (Vertical Scaling)
Skala vertikal (juga dikenal sebagai scale up dan scale down) adalah proses meningkatkan atau menurunkan ukuran mesin virtual sesuai kebutuhan beban kerja.

Contoh Situasi Penggunaan Skala Vertikal:
- Jika Pengguna memiliki layanan yang berjalan di mesin virtual dan penggunaannya rendah saat akhir pekan, Pengguna bisa menurunkan ukuran VM untuk menghemat biaya.
- Saat terjadi lonjakan permintaan, Pengguna bisa meningkatkan ukuran VM tanpa perlu membuat mesin virtual tambahan.
Dengan skala vertikal, satu mesin virtual menjadi lebih kuat (scale up) atau lebih ringan (scale down) untuk menyesuaikan dengan beban.
Skala Horizontal (Horizontal Scaling)
Skala horizontal (juga dikenal sebagai scale out dan scale in) melibatkan penambahan atau pengurangan jumlah instance mesin virtual untuk menangani perubahan beban kerja.

Contoh Penggunaan Skala Horizontal:
- Tambahkan beberapa VM saat trafik tinggi (scale out).
- Kurangi jumlah VM saat beban menurun (scale in).
Skala horizontal memungkinkan sistem tumbuh atau menyusut dengan menambah atau mengurangi jumlah mesin virtual.
Pertimbangan saat Menggunakan Skala Vertikal dan Horizontal
| Pertimbangan | Skala Vertikal | Skala Horizontal |
|---|---|---|
| Batasan | Terbatas oleh ukuran hardware maksimum; VM mungkin perlu direstart. | Umumnya lebih fleksibel; bisa menggunakan banyak VM sekaligus. |
| Fleksibilitas | Kurang fleksibel di cloud; bisa lebih lambat. | Lebih fleksibel; dapat menangani ribuan VM. |
| Reprovisioning | Mungkin diperlukan saat mengganti ukuran VM; bisa menyebabkan downtime. | Perlu rencana untuk penggantian VM dan migrasi data. |
Catatan
Rencana ketersediaan yang kuat perlu mempertimbangkan kapan reprovisioning mungkin diperlukan, serta bagaimana mempertahankan dan melakukan migrasi data jika terjadi penggantian mesin.
Implementasi VM scale sets
Azure Virtual Machine Scale Sets adalah sumber daya komputasi Azure yang memungkinkan Pengguna untuk menerapkan dan mengelola sekumpulan mesin virtual yang identik.
Scale Sets secara otomatis menambah jumlah instance VM saat permintaan meningkat, dan menguranginya saat permintaan menurun, tanpa perlu melakukan pra-konfigurasi manual terhadap semua mesin virtual.
Keuntungan Menggunakan Virtual Machine Scale Sets
- Peningkatan ketersediaan dan skalabilitas aplikasi.
- Skalabilitas otomatis (autoscaling) berdasarkan permintaan.
- Tidak perlu pra-provisioning; cocok untuk aplikasi berskala besar seperti big data, container, dan workload komputasi tinggi.
- Penambahan dan pengurangan instance bisa dilakukan secara manual, otomatis, atau kombinasi keduanya.
Karakteristik Penting Virtual Machine Scale Sets
- Semua instance VM dibuat dari image sistem operasi dan konfigurasi yang sama, memudahkan manajemen ratusan VM tanpa konfigurasi tambahan.
- Mendukung Azure Load Balancer untuk distribusi trafik layer-4, dan Azure Application Gateway untuk layer-7 serta terminasi TLS/SSL.
- Dapat menjalankan beberapa instance aplikasi secara bersamaan — jika satu VM gagal, pelanggan tetap dapat mengakses aplikasi dari instance lainnya dengan gangguan minimal.
- Permintaan aplikasi yang berubah-ubah sepanjang hari/minggu dapat disesuaikan melalui fitur autoscaling otomatis.
- Mendukung hingga 1.000 VM instance jika menggunakan image Azure bawaan, dan hingga 600 instance jika menggunakan image VM kustom.
Catatan
Azure Virtual Machine Scale Sets ideal untuk skenario high availability, efisiensi biaya, dan penskalaan dinamis berbasis beban kerja.
Membuat VM Scale Sets
Pengguna dapat menerapkan Azure Virtual Machine Scale Sets melalui portal Azure. Dalam proses pembuatan, Pengguna akan menentukan jumlah VM, ukuran VM, dan preferensi lain seperti penggunaan Azure Spot Instances, managed disks, serta kebijakan alokasi.
Pengaturan Penting dalam Pembuatan Scale Sets
Saat membuat Virtual Machine Scale Sets di portal Azure, Pengguna akan mengonfigurasi berbagai pengaturan berikut:
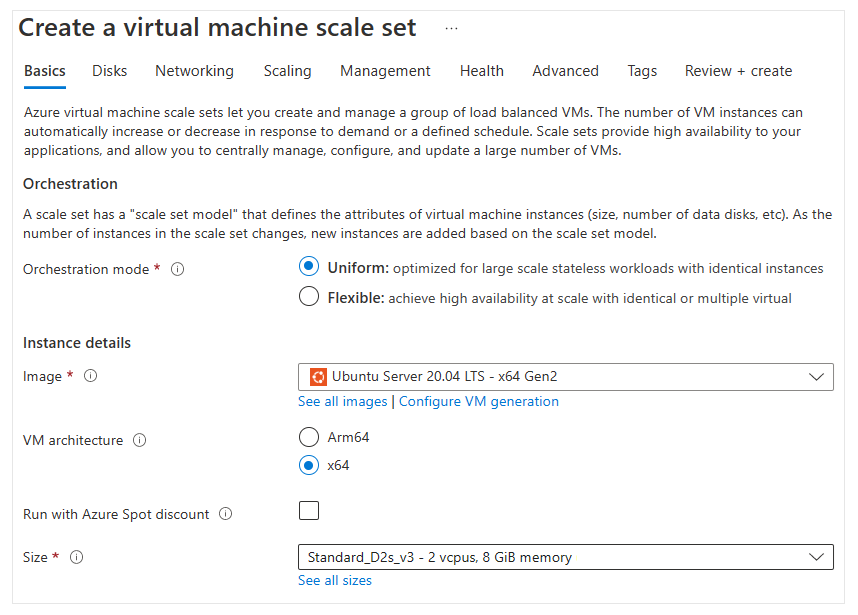
Mode Orkestrasi (Orchestration Mode)
- Flexible: Pengguna dapat menambahkan VM dengan konfigurasi berbeda secara manual ke dalam scale set.
- Uniform: Pengguna mendefinisikan satu model VM, dan Azure akan membuat instance identik berdasarkan model tersebut.
Sistem Operasi (Image)
- Pilih sistem operasi dasar atau aplikasi yang akan digunakan oleh VM.
Arsitektur VM
- x64: Kompatibilitas perangkat lunak paling luas.
- Arm64: Memberikan hingga 50% efisiensi harga/kinerja lebih baik dibandingkan x64 setara.
Ukuran VM (Size)
- Pilih ukuran VM yang sesuai dengan beban kerja Pengguna. Ukuran ini memengaruhi daya komputasi, memori, dan kapasitas penyimpanan.
- Azure menyediakan berbagai pilihan ukuran dan akan mengenakan biaya berdasarkan ukuran dan OS VM per jam.
Pengaturan Lanjutan (Advanced)
Algoritma Penyebaran (Spreading Algorithm)
- Max spreading (disarankan): VM akan disebar sebanyak mungkin ke berbagai fault domain dalam satu zona.
- Fixed spreading: VM akan selalu disebar ke lima fault domain. Jika kurang dari lima tersedia, scale set gagal dibuat.
Rekomendasi
Gunakan Max spreading untuk meningkatkan toleransi terhadap kegagalan dan keberhasilan deployment.
Implementasi autoscale
Dalam implementasi Azure Virtual Machine Scale Sets, Pengguna dapat mengaktifkan proses otomatis untuk menambah atau mengurangi jumlah instance VM berdasarkan permintaan aplikasi. Proses ini disebut autoscaling, yang memungkinkan konfigurasi Pengguna untuk beradaptasi secara dinamis dengan beban kerja yang berubah.
Autoscale membantu meminimalkan jumlah instance VM yang berjalan saat permintaan rendah, sekaligus memastikan performa aplikasi tetap baik saat permintaan meningkat dengan menambah instance VM secara otomatis.
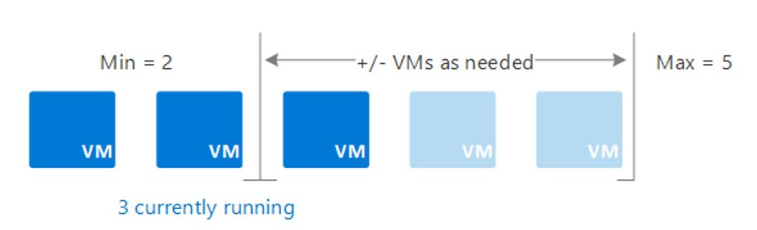
Ilustrasi
Misalnya, Pengguna dapat mengonfigurasi autoscale dengan minimal 2 VM dan maksimal 5 VM, tergantung pada beban kerja aplikasi.
Hal yang Perlu Dipertimbangkan Saat Menggunakan Autoscaling
1. Penyesuaian Kapasitas Otomatis
Pengguna dapat membuat aturan autoscale berdasarkan metrik performa seperti CPU usage atau penggunaan memori. Ketika ambang batas tertentu tercapai, aturan autoscale akan menyesuaikan kapasitas VM Scale Set Pengguna secara otomatis.
2. Scale Out (Menambah Instance)
Jika permintaan terhadap aplikasi meningkat secara konsisten, Pengguna dapat mengonfigurasi aturan untuk meningkatkan jumlah VM dalam Scale Set agar beban kerja dapat ditangani dengan baik.
3. Scale In (Mengurangi Instance)
Ketika permintaan menurun, seperti pada malam hari atau akhir pekan, aturan autoscale dapat mengurangi jumlah VM untuk menghemat biaya — Pengguna hanya menjalankan instance yang diperlukan untuk memenuhi permintaan saat ini.
4. Penjadwalan (Scheduled Events)
Pengguna juga dapat menjadwalkan waktu tertentu untuk menambah atau mengurangi kapasitas secara otomatis, misalnya selama jam kerja atau promosi online.
5. Pengurangan Beban Administratif
Dengan autoscaling, Pengguna tidak perlu terus-menerus memantau dan menyesuaikan performa aplikasi secara manual. Ini mengurangi overhead manajemen dan memastikan aplikasi tetap optimal tanpa intervensi langsung.
Catatan
Autoscaling merupakan fitur kunci untuk menjaga efisiensi biaya, kelincahan sistem, dan pengalaman pengguna yang konsisten.
Konfigurasi autoscale
Saat Pengguna membuat implementasi Azure Virtual Machine Scale Sets melalui portal Azure, Pengguna dapat mengaktifkan skala manual atau otomatis (autoscaling). Untuk performa yang optimal, Pengguna sebaiknya menetapkan jumlah minimum, maksimum, dan default instance mesin virtual (VM) yang akan digunakan.
Mode Skala
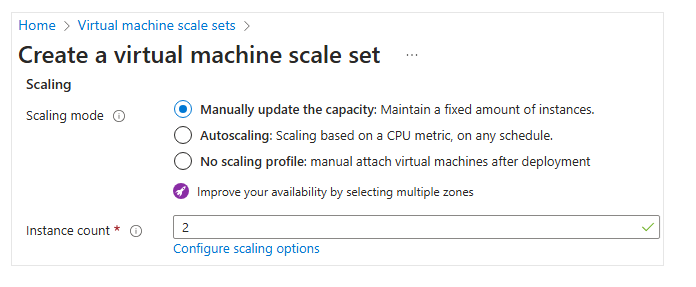
Di portal Azure, Pengguna dapat memilih mode skala yang diinginkan.
-
Perbarui kapasitas secara manual: Pengguna dapat memperbarui kapasitas secara manual dan mempertahankan jumlah instance tetap. Setel jumlah instance sesuai kebutuhan (antara 0–1000).
Pengguna juga dapat mengonfigurasi kebijakan scale-in, yaitu urutan VM yang dipilih untuk dihapus. Misalnya, Pengguna dapat menyebarkan beban secara merata antar zona dan menghapus VM dengan Instance ID tertinggi. -
Autoscaling: Pengguna dapat mengaktifkan autoscale berdasarkan jadwal atau metrik. Tentukan jumlah maksimum instance VM yang dapat tersedia ketika autoscaling aktif pada implementasi Pengguna.
Konfigurasi Autoscale
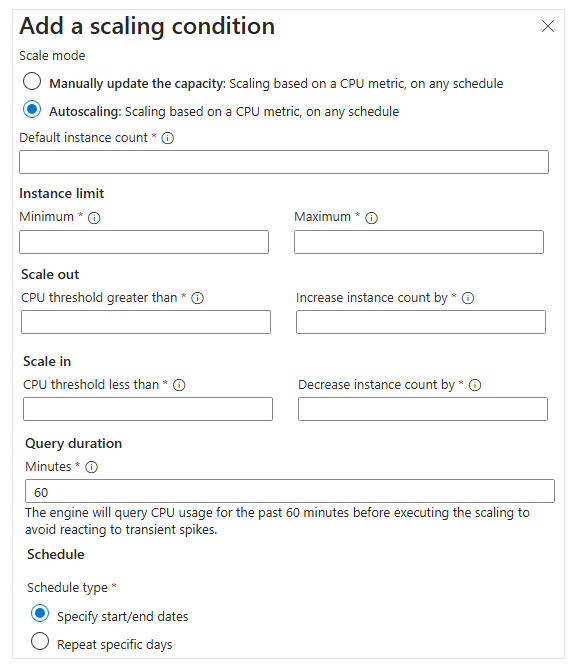
Autoscaling diatur berdasarkan kondisi penskalaan tertentu.
-
Default instance count: Jumlah awal VM yang diterapkan dalam scale set (antara 0–1000).
-
Batas instance:
- Minimum: Jumlah minimum instance saat penskalaan turun (scale-in).
- Maksimum: Jumlah maksimum instance saat penskalaan naik (scale-out).
-
Scale Out (Naik Skala):
- Persentase ambang batas penggunaan CPU untuk memicu aturan scale-out.
- Jumlah instance baru yang akan ditambahkan ketika aturan terpenuhi.
-
Scale In (Turun Skala):
- Persentase ambang batas penggunaan CPU untuk memicu aturan scale-in.
- Jumlah instance yang akan dikurangi ketika aturan terpenuhi.
-
Durasi (Query Duration):
Ini adalah waktu peninjauan rata-rata penggunaan metrik oleh mesin Autoscale. Durasi ini memungkinkan data metrik Pengguna untuk distabilkan sebelum aturan diterapkan. -
Penjadwalan (Schedule):
Pengguna bisa menetapkan tanggal mulai dan akhir autoscale. Jadwal ini juga dapat diulang pada hari-hari tertentu sesuai kebutuhan bisnis Pengguna.
Gunakan autoscaling untuk meningkatkan efisiensi biaya dan kinerja sistem dengan menyesuaikan kapasitas VM secara dinamis sesuai beban kerja.
Perencanaan maintenance dan downtime
Rencana ketersediaan untuk mesin virtual Azure perlu mencakup strategi untuk pemeliharaan perangkat keras yang tidak direncanakan, waktu henti yang tidak terduga, dan pemeliharaan yang direncanakan.
Pemeliharaan Perangkat Keras yang Tidak Direncanakan
Kejadian pemeliharaan perangkat keras yang tidak direncanakan terjadi ketika platform Azure memprediksi bahwa perangkat keras atau komponen platform yang terkait dengan mesin fisik akan mengalami kegagalan. Ketika platform memprediksi kegagalan, Azure mengeluarkan kejadian pemeliharaan perangkat keras yang tidak direncanakan menggunakan teknologi Live Migration untuk memigrasikan mesin virtual dari perangkat keras yang akan gagal ke perangkat fisik yang sehat.
Live Migration adalah operasi yang mempertahankan mesin virtual yang hanya menjeda mesin virtual dalam waktu singkat, namun kinerja dapat menurun sebelum atau sesudah kejadian tersebut.
Waktu Henti yang Tidak Terduga
Waktu henti yang tidak terduga terjadi ketika perangkat keras atau infrastruktur fisik untuk mesin virtual gagal secara tiba-tiba. Waktu henti yang tidak terduga dapat mencakup kegagalan jaringan lokal, kegagalan disk, atau kegagalan di tingkat rak lainnya. Ketika terdeteksi, platform Azure secara otomatis memigrasikan (menyembuhkan) mesin virtual Pengguna ke mesin fisik yang sehat di data center yang sama. Selama proses penyembuhan ini, mesin virtual akan mengalami waktu henti (reboot) dan dalam beberapa kasus kehilangan drive sementara.
Pemeliharaan yang Direncanakan
Kejadian pemeliharaan yang direncanakan adalah pembaruan berkala yang dilakukan oleh Microsoft pada platform dasar Azure untuk meningkatkan keandalan, kinerja, dan keamanan infrastruktur platform tempat mesin virtual yang dijalankan.
Microsoft tidak secara otomatis memperbarui sistem operasi mesin virtual atau perangkat lunak lainnya. Pengguna memiliki kendali penuh dan tanggung jawab terhadap pembaruan tersebut. Namun, perangkat lunak host dan perangkat keras dasar secara berkala diperbarui untuk memastikan keandalan dan kinerja tinggi.